- News
- Introduction
- Important Dates
- Programme
- Topics of Interest
- Pioneering the Linked Open Research Cloud
- Submissions
- Proceedings
- Organising Committee
- Programme Committee
- Previous Workshops
![]()
![]()
The Web is developing from a medium for publishing textual documents into a medium for sharing structured data. This trend is fueled on the one hand by the adoption of the Linked Data principles by a growing number of data providers. On the other hand, large numbers of websites have started to semantically mark up the content of their HTML pages and thus also contribute to the wealth of structured data available on the Web.
The 10th Workshop on Linked Data on the Web (LDOW2017) aims to stimulate discussion and further research into the challenges of publishing, consuming, and integrating structured data from the Web as well as mining knowledge from the global Web of Data.
On the 10th anniversary of the LDOW workshop series, we look back on a decade of Linked Data research, and the broader technical and commercial impact of Linked Data principles and technologies.
The timing for presentations and breaks at LDOW2017 is shown below.
Topics of interest for the workshop include, but are not limited to, the following:
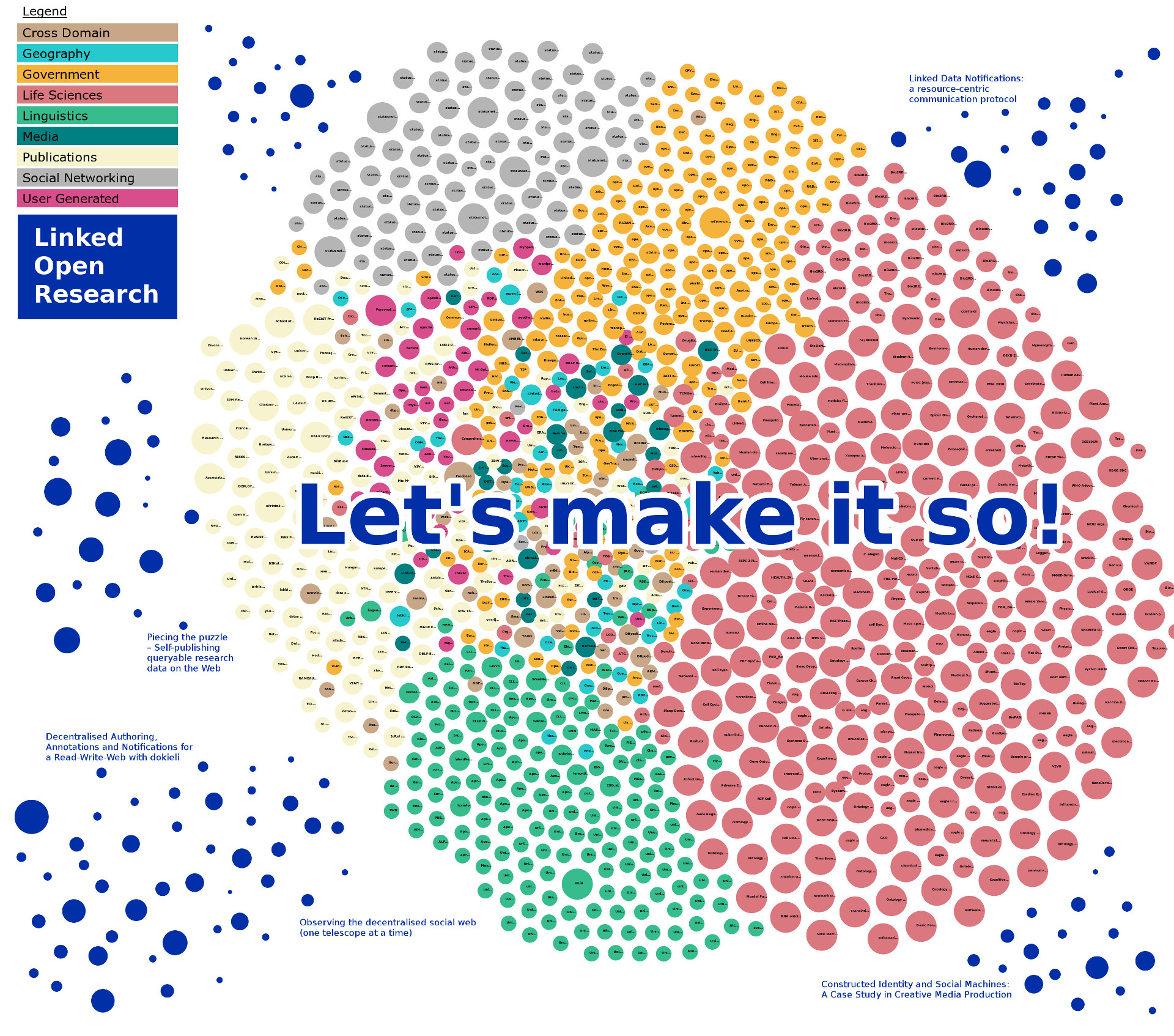
Web Data Quality AssessmentProblem: The LOD Cloud contains minimal information about the research output from Web Science, Semantic Web, and Linked Data venues (including, a decade on, our very own LDOW workshop). Moreover, our interactions with these publications are static, and not very social. Simply put, we are not taking full advantage of what the Web enables us to do, let alone applying our own tools and standards to publish, consume, or enhance the output.
Challenge: What if we were to semantically capture the core parts of our research at a granular level, and offer user interactions and participation? Could this help to improve our work, and bring the community to new levels of understanding, and increase usage of tools and techniques? What if we were able to search or query for these parts? We might be able to answer questions such as: "Which scholarly articles are relevant to my research?", "What is the hypothesis of a given article?", "Which other researchers might find my results/output directly useful?", "What new ways are there to cluster related research together?", "Is there a research gap on a topic of interest?"
Proposal on how to proceed: Progress has been made with regards to gathering and using metadata (eg., author names, article titles, year, abstract) - see the Semantic Web Dogfood / ScholarlyData - but we need to take this to a new level. We strongly promote self-dogfooding, encouraging authors to demonstrate that they use Semantic Web tooling or techniques in their own practice. We also promote decentralisation and data ownership, and encourage participants to submit their contribution by publishing a document at a domain they control or consider sufficiently authoritative (e.g., a university webpage), and sending us the URL. Reviews will be based on a persistent copy of submitted URLs e.g., from an archive.org snapshot of the article at the submission deadline. See Submissions below for more information.
We seek the following kinds of submissions:
Submissions must be formatted using the ACM SIG template (as per the WWW2017 Research Track) available at http://www.acm.org/sigs/publications/proceedings-templates:
Please submit papers via EasyChair at https://easychair.org/conferences/?conf=ldow2017
Alternatively: Write your article for example in HTML and annotate with RDFa/Turtle/JSON-LD as you see fit. Publish datasets and similar results openly (e.g., in a public repository) and available as Linked Data. For authoring according to the Linked Research principles, authors can use dokieli - a decentralised authoring and annotation tooling (see source). HTML based contribution can be submitted by either providing an URL to the article (in HTML+RDFa, CSS, JavaScript etc.) with supporting files, or an archived zip file including all the material. There are a variety of examples available online, where the ACM author guidelines as a template may be particularly useful.
Please note that the author list does not need to be anonymized, as we do not operate a double-blind review process. Submissions will be peer reviewed by at least three independent reviewers. Accepted papers will be presented at the workshop and included in the workshop proceedings. At least one author of each paper is expected to register for the workshop and attend to present the paper.
Accepted paper will be made available one this website and be published as a volume of the CEUR series of workshop proceedings.